

2·
2 days agoMega-Embassy
Very funny to think the problem people have with the embassy is it’s size and not it’s “China”
Victim of Communism
Mega-Embassy
Very funny to think the problem people have with the embassy is it’s size and not it’s “China”

A great deal of the industry is powered by debt financing. And the CEO typically holds the job by gatekeeping access to that borrowed money.
Labor solidarity is predicated on being able to participate in the market. It isn’t as if people don’t try to Unionize. But if your office or your business or your entire industry can be casually strangled to death by the financial sector when a plurality demand a raise, there’s quickly nothing left to unionize.
Maybe. Or maybe companies like EA would implode under their own dysfunction and leave a multi-billion dollar hole in the industry for China to fill.
A lot of American companies do seem willing to commit suicide before they pay their workers equitably
Excited for Battlefield 7
When you’re working on a big enough project, you’ll inevitably find yourself acting as a condom between people who don’t understand your niche field and the thing you’re all building together.
That’s not unique to Claude. However, the fact that Claude can drop big salty loads far faster than you can catch them does present additional challenges.
I thin we can all agree there is a happy middle ground
I don’t think there IS a middle ground. These are two very distinct historical styles. And if you tried to find a spot in the middle, everything would clash and it would look horrendous.
Nice and personal… Soulless.
Is a black/white color actually scheme soulless? Or is it merely the absence of clutter, no accumulation of wear-and-tear, and the blue filter used for the lighting?
Put six people in that black/white house for a week and it’ll be a cluttered mess. Throw a yellow-filter on the lighting and it’ll look more warm and inviting.
You know, Israel.
Israel has been more than happy to sell arms and other military services to either side. It’s pure war profiteering.
I’m surprised trump hasn’t tried starting something similar
Rubio has been standing up all sorts of horrifying prison and forced labor pipelines across Latin America and into the Pacific Rim.
Nevermind ICE itself, which has just become a factory for turning disaffected, unemployed Fox News millennials onto roided up paramilitary death squads.
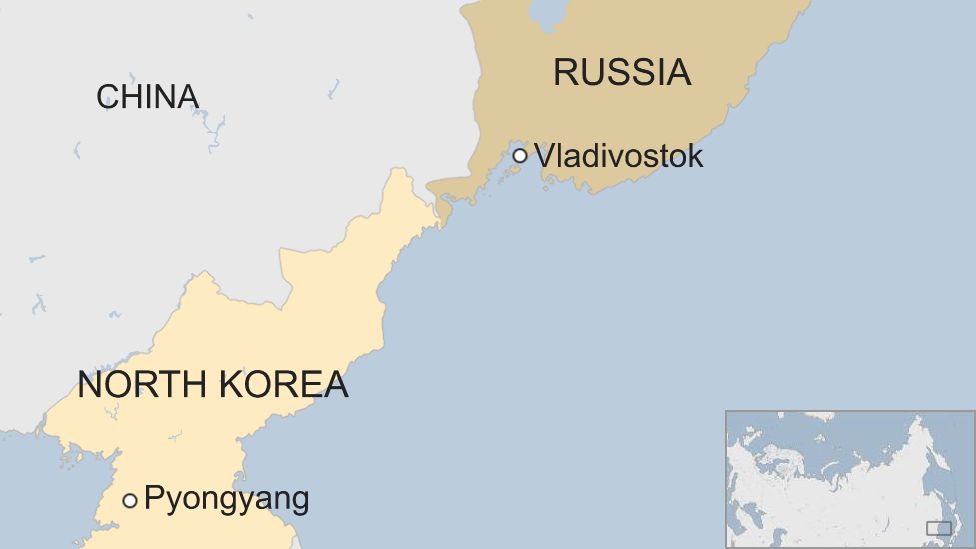
TIL. That’s an incredibly tiny border.
China is much likely cooking the books
I see this line repeated ad nauseum, with vanishingly little to back it up.
As it is detailed in the research report
That’s a dead link for me.
the total number of immigrants amounted to just 0.1% of China’s population of more than 1.41 billion people.
If every single Italian in the country moved to China tomorrow, they could bump that number up to 0.15%
Brussels has been examining ways to shield European industry from what many manufacturers say is the negative fallout from China’s industrial overcapacity and subsidised exports.
So happy to see the German government finally embracing the way, the truth, and the light of Juche Thought
Italy, the world’s fourth-largest machine tool exporter, also lost ground over the period. Its share of global exports slipped to 7.8% in 2025 from 8.4% in 2016, while Italian exports to China plunged to €110 million from €316 million.
One of the jokes about the Italian economy is that it does a phenomenal job of raising, educating, and training young people. But it does a dogshit job of actually paying them. Consequently, a significant number of professionally trained Italian engineers, IT specialists, and other highly educated workers find themselves moving to China in order to pursue the careers they trained for at the Universities of Bolonga and Milian. Shanghai, in particular, has an enormous European expat community.
So there’s a very good chance the machine tools Italians have lost the edge in the market producing are coming from the very same tool makers that they used to employ.

It definitely shows how bad the state of the national news media is. We’re watching The Trump Show 24/7/365. I doubt one American in twenty could even name a Dem contender for President who hasn’t run already. One reason why Kamala Harris remains a front-runner on paper. Hell, you’ll see people talk about Hillary Clinton, Bernie Sanders, and Barack Obama running again, purely because these are the only people whose names register.
But come primary season, that will change as contenders put more money and social pressure on boosting their own name recognition. This time next year, you’ll have a dozen different Dem contenders doing their warm-up laps around the field. If AOC isn’t running, I doubt she’ll be seriously missed.
I just don’t think she deserved to get the kind of attention she’s getting.
A lot of it boils down to her fundraising numbers. Among all the members of The Squad, she outperforms to the point that the rest of the party needs to periodically come to her with hands out for a cup of money. That extends her influence within party leadership and allows her to effectively lobby for legislative amendments and rally support in her caucus to vote against certain other bills.
For example many people talk about presidency and I think she’s not even close to this level.
I think she’s better positioned to work on her bid in 2026 than Obama was twenty years earlier.
Of course, I also think she’d function better as a candidate for NY Governor. Building a hard base of DSA-aligned Democrats inside New York and advancing progressive policy at the state level sounds much more appealing than taking a stab at the White House, only to get the entire country’s problems dumped in your lap.
There’s simply no one else out there.
There’s Pritzker in Illinois and Andy Beshear in Kentucky. Chris Murphy of Connecticut and Mark Kelly of Arizona are also strong contenders. But, again, anyone taking the Presidency in 2028 is going to inherit an absolute shitshow. I wouldn’t want the job and I think you kinda have to be crazy if you do. I also don’t think AOC would do well under the degree of pressure the office will apply. You really need someone coming in there with a crowbar and an eye for kneecaps. That’s not her style of politics.
I could almost stomach four years of Gavin Newsom if I believed he’d spend his time running down Trump Admin hacks and bankrupting them. Where’s Elliot Spitzer when you need him? But I know Newsom would sell out twice as hard as Trump just to prove he’s better at it, so that’s a no-go.
I don’t think there are any good candidates for President in 2028, AOC included. But that’s more thanks to the deep endemic corruption of the office and the spinelessness of the Dem Party as a whole. If the only thing you care about is winning a popularity contest, though? AOC’s a top contender.
that worked on Hillary
Hillary shot herself in the foot by holding repellent policies and abhorrent views even within her own party. She was pro-war well into the 2010s. She was Tough On Crime in the middle of BLM protest waves. She was chintzy and hyper-bureaucratic on public health care and education while she freely opened her wallet to mass surveillance and corporate bailouts. She demonstrated naked hostility to the LGBTQ community time and time again. She flaunted her wealth, constantly lied about her own historical record, surrounded herself with sycophants and scammers, and was the worst kind of sore loser.
That’s why Obama kicked the knees out from under her in 2008. And that’s why Donald Trump could casually outflank her on the left in 2016, by mouthing a few anti-war slogans, bullshitting about popular economic reforms, and hugging the Pride Flag. Hillary made the same stupid mistakes as Gore in 2000 and Kerry in 2004 and Harris in 2024. She desperately pandered to the Republican Establishment while expecting everyone to the left of John McCain to reflexively bend the knee.
I’m glad Hillary lost. I’m just sad she had to lose in the general, rather than scrubbing out in the primary a second time.
She’s not a great speaker but she gets a lot of coverage from left-wing influencers because there’s no one else to promote.
She’s fine. There are definitely better orators. But she stays on message, advances popular policies, and is generally well-received by her constituents. There are plenty of other aspiring AOCs that don’t perform half as well. And you won’t be able to name them because they don’t win elected office - much less survive multiple hostile intra-party primary bids and smear campaigns - or fundraise effectively or get promoted via social media so aggressively.
There are definitely other people to promote. We just watched Graham Platner’s star rise largely on his personal charisma and ability to build a crowd. We’ve seen Al Franken and Anthony Weiner and John Edwards all come and go along similar trajectories. AOC might demonstrate better staying power simply because she’s not a giant sex pest.
So she’s everywhere even though she’s kind of bland in my opinion (compared with European left at least).
Compared to Corbyn or Mélenchon or Reichinnek? I’d say she’s par for the course.
Plenty of politicians exist who have sensible policies and speak truth to power and yadda yadda yadda. Most of them lose. The ones that win mostly get back-benched by party leadership or primaried out of office in subsequent elections.
AOC (and Sanders and Mamdani and a few others) tend to be notable because they advance popular policies in a manner that cut through corporate media white noise, while surviving a deluge of character attacks and faux-scandals intent on derailing their mission.
It’s not merely that you have some rando saying shit. It’s that you can hear that person, you can be represented by that person, and you can organize around that person to elect other politicians with a similar set of values and beliefs.
Can’t believe the county that can’t produce anything is having munition shortage issues





{kind=link}
{kind=link}
Jellyfin doesn’t have this problem